Speed, Quality, Dev Time... pick two. This has been an age-old tradeoff in software development. The goal of this blog post is to create a local dev environment for ad-hoc gpu-cluster computing using Apache Spark, iPython Notebook (scala version), and the stock GPU powering your Macbook Pro's display.
Make it work... then make it fast... then make it beautiful -- Matthew Russell
In the spirit of my mentor, we will start by getting each part "working" individually. Fortunately, the second part (speed) sortof falls out of the first (GPU clusters are like that). Then, we'll integrate these parts into something beautiful... a scalable, ad-hoc environment.
Part 1: Spark-Notebook
Apache Spark can be controlled by notebooks from several languages. I'm going with Scala for several reasons. First, it allows me to have access to the full Spark API (Graphx support is a dealbreaker for me). Secondly, the only GPU library that allowed me to compile for the GPU without writing C code myself is in Java (which I can call from scala). Even with these limitations, there were still several to choose from. The options were:
Zeppelin -> buggy API after I imported classes
Spark-Notebook -> headache to import dependencies
Sparknotebook -> Winner!!! Killer app.
After cloning the Sparknotebook repo and following its instructions (downloading the IScala.jar...etc), with a single command I could open the notebook on top of a standalone spark cluster... easy peasy...
Please go like the REPO... I'd like to see it get some love....
Part 2: GPU on the JVM
The inspiration for this came from a rather impressive library called ScalaNLP. They claimed to have a parser that could parse half a million words per minute on one machine! Given that I work in R&D at a "Big-Data NLP" firm, this peaked my interest. Scalanlp on a 100 node cluster seems.... rather disgustingly awesome.
ScalaNLP Leverages the java opencl library, JavaCL. The decision to use OpenCL, as opposed to CUDA, means that the code runs on non-NVIDIA graphics cards. All Apple's can use OpenCL. Therefore, I can prototype on my Macbook's GPU. I like that.... i like that a lot.
However, what I don't like is writing C code. It slows me down and isn't portable. I need my code to be both enterprise-ready and, "we don't want to buy GPUs" ready. This is where Aparapi comes in. It compiles Java code down to OpenCL, and runs it in a Java Thread Pool if a GPU isn't available. Also, it's made by AMD... which means you can trust it. Those guys are total bosses. AMD Claims New World Record
I downloaded the AparaPi Mac OS Zip... although all these are available.
Aparapi_2012_01_23_MacOSX_zip
Aparapi_2013_01_23_linux_x86.zip
Aparapi_2013_01_23_windows_x86.zip
I unzipped the download into a folder on my machine, and it created a folder called "Aparapi_2012_01_23_MacOSX_zip".
Executions:
cd Aparapi_2012_01_23_MacOSX_zip/samples/squares/Output Sample:
sh squares.sh
Execution mode=GPU
0 0
1 1
2 4
3 9
4 16
5 25
6 36
7 49
8 64
9 81
10 100
Wallah! Apparently this java code can run on my Macbook's GPU. Feel free to try a few of the other sample programs... the mandlebrot one is super cool!
Part 3: Integrating Spark and Aparapi in the Notebook
So, everything so far has simply been a tutorial on "proper tool selection" for the task. The real challenge is in getting these tools to talk to each other. The first integration step we need to do is to import the aparapi jar into the iscala notebook. This can be done using the following command.
mvn install:install-file -Dfile=aparapi.jar -DgroupId=com.amd.aparapi -DartifactId=aparapi -Dversion=1.0 -Dpackaging=jar
Furthermore, my ~/.ipython/profile_scala/ipython_config.py looks like this at the bottom...
c = get_config()
c.KernelManager.kernel_cmd = ["java","-Djava.library.path=/Users/.. .../Aparapi_2012_01_23_MacOSX_zip","-XX:MaxPermSize=2048m","-Xmx8g",
"-jar", "/Users/myname/.ipython/profile_scala/lib/IScala.jar","/Users/... .../Aparapi_2012_01_23_MacOSX_zip/aparapi.jar",
"--profile",
"{connection_file}",
"--parent"]
This gets the aparapi jar on our spark cluster classpath.
One more detail, when you're starting ipython notebook, start it with this command (with your aparapi zip directory path instead of mine). I'll go into this in a minute
SPARK_DAEMON_JAVA_OPTS=-Xmx8128m SPARK_WORKER_MEMORY=-Xmx2048m SPARK_DAEMON_MEMORY=-Xmx2048m SPARK_REPL_OPTS=-XX:MaxPermSize=2048m SBT_OPTS=-Xmx8128m SPARK_JAVA_OPTS="-Djava.library.path=/Users/... ..../Aparapi_2012_01_23_MacOSX_zip -Xms512m -Xmx8128m" ipython notebook --profile scala
When I deploy the aparapi jar locally, I can then import aparapi like so...
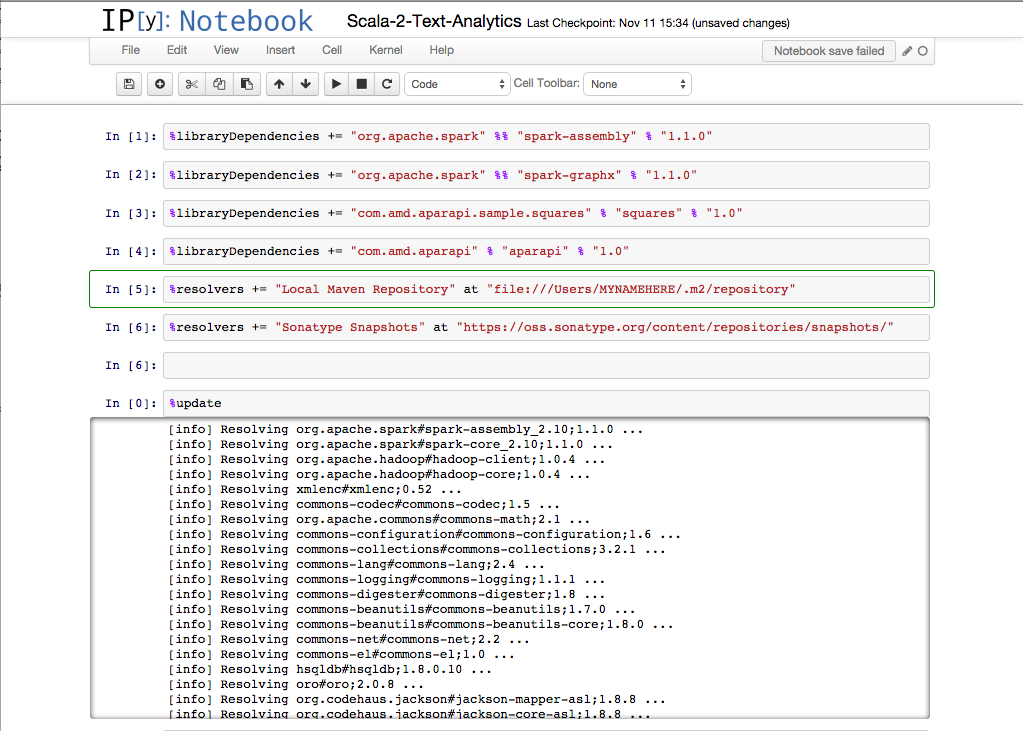
GPU, iPython Notebooks, and Apache Spark meeting for the very first time ever…. a moment in history.
Assuming no errors in the "upload" command (scroll to the bottom for a list of any import failures), you should be good to go. Also, notice that I'm using the demo scala notebook from the sparknotebook github. I recommend this to make sure that the notebook is working before you start.
Part 4: Example Kernel Built in the Notebook (using Scala only)
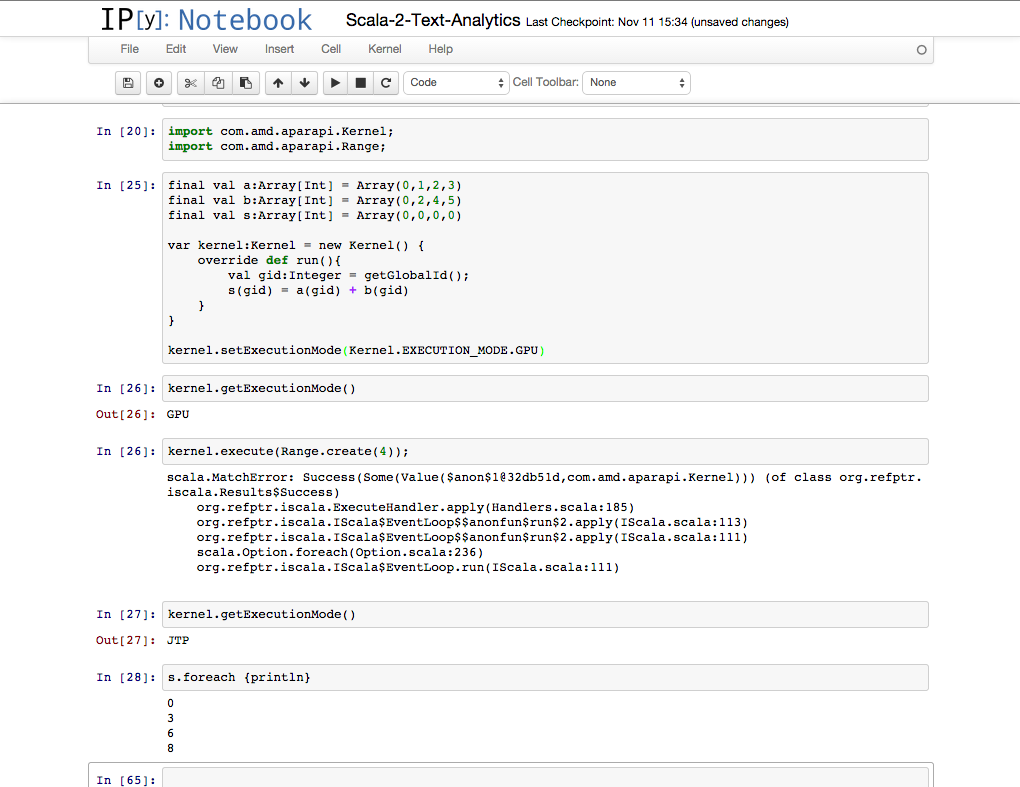
Building a kernel and running it… notice the output at the bottom…
Notice that i tried to set the kernel to run on the GPU, but because the GPU wasn't available, it switched the version and ran it on the CPU. You might be thinking, "Wait!!! This blog is a hoax!!!". I got a bit discouraged at this point as well, however, debugging later found out that we cannot compile Scala to GPU code. This is acceptable for prototyping kernels and chaining them together. This will even run in the spark context... so to develop and test your kenels (using the Java Thread Pool fallback), feel free to do it this way.
Part 5: Executing GPU Kernel on Spark Cluster
Now the moment we've all been waiting for.... earlier when you installed the aparapi jar into maven, you were actually installing the compiled jar including the "Square" sample code. If we crack open the "squares.sh" script we ran earlier, we'll see that it is calling a program in that jar
squares.sh
java \
-Djava.library.path=../.. \
-Dcom.amd.aparapi.executionMode=%1 \
-classpath ../../aparapi.jar:squares.jar \
com.amd.aparapi.sample.squares.Main
This means that the compiled code is already on our classpath... and we can call it from a spark method like so...
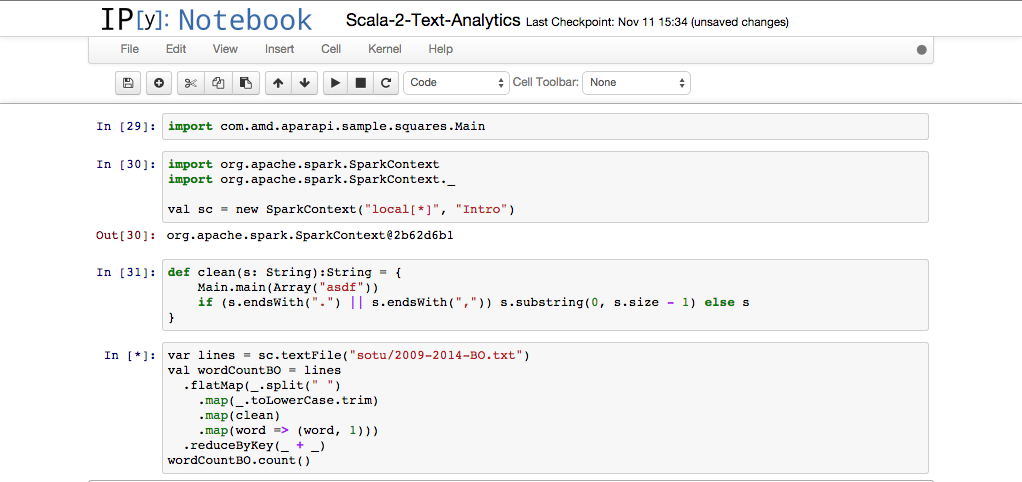
Running the kernel in the ipython notebook via spark
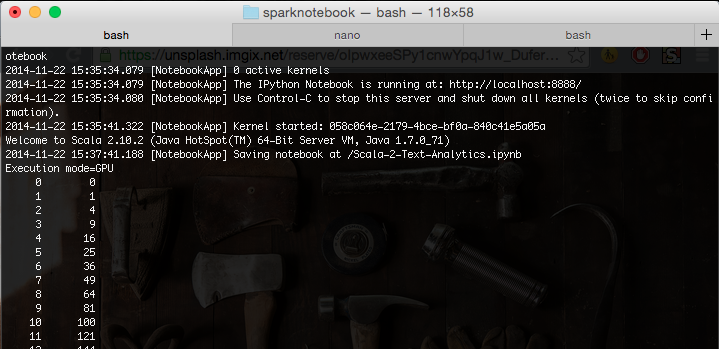
The logging of the GPU program… showing that it is indeed being run on the GPU (didn’t fallback to JTP)